
What Is Data Annotation? The Complete Guide for AI Teams in 2026
Every time you ask a voice assistant a question, unlock your phone with your face, or get a product recommendation online — you’re experiencing the result of millions of meticulously labelled data points.
That labeling process has a name: data annotation.
It’s one of the least glamorous — and most critical — steps in building AI that actually works. Without it, even the most powerful machine learning model is essentially blind. This guide breaks down everything you need to know about data annotation in 2026: what it is, how it works, the different types, and why more businesses are choosing to outsource it rather than tackle it in-house.
What Is Data Annotation?
Data annotation is the process of labeling, tagging, or classifying raw data — images, text, audio, or video — so that machine learning algorithms can interpret and learn from it.
Think of it as teaching a child to recognize a cat. You don’t explain feline biology. You point at hundreds of cats and say, “That’s a cat.” Over time, the child learns to recognize cats on its own.
AI works the same way. An image recognition model needs thousands of images where someone has already drawn boxes around objects and labeled them: car, pedestrian, traffic light. A sentiment analysis tool needs thousands of customer reviews marked as positive, negative, or neutral.
Data annotation is, simply put, how humans teach machines to understand the world.
Why Data Annotation Is the Backbone of AI
There’s a reason data scientists spend more time preparing data than building models. The quality of your training data determines the ceiling of your model’s performance — no matter how sophisticated your architecture.
High-quality annotation delivers three core outcomes:
- Greater model accuracy — Well-labeled data helps models learn the right patterns and avoid false associations.
- Reduced bias — Carefully annotated, diverse datasets catch the gaps and imbalances that cause AI to behave unfairly or inconsistently.
- Better generalization — Models trained on clean, structured data perform reliably on new, unseen inputs — not just the training set.
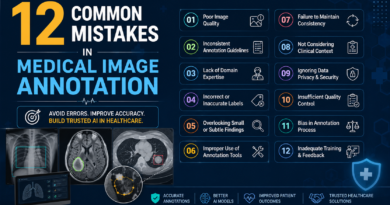
Poor annotation, on the other hand, introduces noise that’s nearly impossible to reverse once a model is trained. Garbage in, garbage out — it’s the oldest rule in computing, and it’s never been more relevant.
Types of Data Annotation (And Where They’re Used)
Different AI applications require different kinds of labeled data. Here’s a breakdown of the major annotation types and their real-world use cases.
-
Image Annotation
Image annotation involves identifying and labeling objects, regions, or features within images. Common techniques include:
- Bounding boxes — Drawing rectangles around objects (used heavily in object detection)
- Semantic segmentation — Labeling every pixel in an image by category
- Polygon annotation — Tracing irregular shapes around complex objects
- Landmark annotation — Marking key points on a face or body for pose detection
Used in: Autonomous vehicles, medical imaging (tumor detection, X-ray analysis), retail AI (visual search, shelf monitoring), and drone technology.
-
Text Annotation (NLP)
Natural language processing models need human-labeled text to understand meaning, intent, and context. Key text annotation types include:
- Sentiment analysis — Marking text as positive, negative, or neutral
- Named entity recognition (NER) — Identifying people, organizations, locations, dates
- Intent classification — Labeling the purpose behind a user query
- Coreference resolution — Linking pronouns back to the entities they refer to
Used in: Chatbots, search engines, customer support automation, document intelligence, and legal AI tools.
-
Audio Annotation
Audio annotation transforms spoken or ambient sound into structured data that AI can process. This includes:
- Speech-to-text transcription — Converting spoken words into written text
- Speaker diarization — Identifying who is speaking at any given moment
- Emotion and tone detection — Tagging audio clips for emotional cues
- Sound event labeling — Identifying background sounds (sirens, music, crowd noise)
Used in: Voice assistants, call center analytics, transcription services, and accessibility tools.
-
Video Annotation
Video annotation extends image annotation across time, requiring frame-by-frame analysis and temporal consistency. It includes:
- Object tracking — Following objects across frames as they move
- Action recognition — Labeling specific human or vehicle behaviors
- Scene classification — Tagging environments and contexts
Used in: Surveillance systems, sports performance analytics, AR/VR development, and autonomous vehicle training.
The Data Annotation Process: Step by Step
Professional data annotation isn’t just about hiring people to click labels. It follows a structured workflow designed to maximize accuracy and consistency.
Step 1: Data Collection
Raw data is gathered from relevant sources — cameras, web scraping, APIs, sensors, or proprietary databases. The goal is to collect data that reflects the real-world conditions the model will face.
Step 2: Data Preparation
Before annotation begins, data is cleaned, de-duplicated, and organized. Irrelevant or low-quality samples are filtered out. This step protects annotation quality downstream.
Step 3: Guideline Development
Annotators follow a detailed labelling guide that defines every edge case. For example: “If a car is more than 80% occluded by another object, do not annotate it.” Ambiguity at this stage becomes inconsistency in the dataset.
Step 4: Annotation
Annotators label the data using specialized tools — whether that’s a bounding box editor, an NLP tagging platform, or an audio transcription interface. Complex tasks often involve multiple annotators per data point to cross-check results.
Step 5: Quality Assurance
Finished annotations go through multi-layer QA: automated checks flag outliers, and human reviewers audit samples for accuracy and consistency. Inter-annotator agreement scores are used to benchmark quality.
Step 6: Delivery
The final structured dataset is exported in the format required for model training — JSON, CSV, XML, COCO, Pascal VOC, and so on — and handed off to the AI development team.
Each step in this process has a direct impact on AI model performance. Skipping or rushing any phase tends to surface as costly model errors later.
Key Benefits of Data Annotation for Businesses
Investing in high-quality data annotation isn’t just a technical necessity — it delivers measurable business value.
Faster AI development cycles. Clean, well-structured training data reduces the time data scientists spend debugging model failures caused by label noise.
Higher model reliability. AI systems built on quality-annotated data perform consistently, which is especially important in regulated sectors like healthcare, finance, and autonomous systems.
Lower long-term costs. Fixing a poorly trained model is far more expensive than getting the annotation right the first time. Quality upfront prevents costly retraining cycles.
Competitive differentiation. Companies with superior training data build better AI products. In industries where AI is table stakes, annotation quality is one of the few durable competitive advantages.
Scalable AI pipelines. Properly annotated datasets can be reused, expanded, and refined — making each new model iteration faster and less expensive than the last.
In-House vs. Outsourced Data Annotation: A Practical Comparison
Many teams initially assume they can handle annotation internally. Here’s what that decision actually looks like in practice:
| Factor | In-House | Outsourced |
| Upfront cost | High (tools, hiring, training) | Lower (pay per project or volume) |
| Speed | Slow to scale | Rapid deployment |
| Scalability | Constrained by headcount | Elastically scalable |
| Domain expertise | General | Specialized by industry |
| Quality control | Variable | Structured QA processes |
| Management overhead | Significant | Minimal |
For most AI teams, outsourcing makes strategic sense — especially for large-scale or time-sensitive projects where building internal capacity isn’t feasible.
Why Businesses Are Outsourcing Data Annotation in 2026
The scale demands of modern AI have fundamentally changed the annotation equation.
A single autonomous vehicle project can require tens of millions of annotated video frames. A conversational AI product needs labeled interactions across dozens of languages and dialects. A medical imaging model demands annotations reviewed by domain experts.
No internal team — regardless of size — can match the throughput, specialization, and cost efficiency of a dedicated annotation partner. That’s why leading AI companies treat data annotation as a managed service rather than an internal function.
Outsourcing transforms annotation from a resource-intensive bottleneck into a scalable, on-demand capability.
How to Choose the Right Data Annotation Partner
Not all annotation vendors are equal. When evaluating providers, look for:
Demonstrated accuracy standards — Ask for sample work and benchmark accuracy rates. Reputable vendors should be transparent about inter-annotator agreement scores.
Domain specialization — A vendor experienced in medical imaging will outperform a generalist on radiology annotation tasks. Match vendor expertise to your use case.
Scalable workforce — The vendor should be able to ramp up capacity quickly without sacrificing quality when project volumes spike.
Data security and compliance — Ensure the vendor follows data protection regulations relevant to your industry (GDPR, HIPAA, etc.) and has clear data handling policies.
Advanced tooling — Modern annotation platforms with AI-assisted pre-labeling significantly accelerate throughput without compromising human oversight.
QA transparency — A reliable partner will show you their QA process, not just the finished output.
The Future of Data Annotation
The annotation industry is evolving rapidly, but not in the direction some expect.
AI-assisted annotation is accelerating workflows — models pre-label data, and humans review and correct rather than labeling from scratch. This hybrid approach is becoming the standard for high-volume projects.
Multimodal datasets are growing in importance as AI systems are increasingly required to reason across text, images, audio, and structured data simultaneously.
Synthetic data generation is emerging as a complement to human annotation for edge cases — but it hasn’t replaced the need for human-labeled real-world data, and industry consensus suggests it won’t for critical applications.
One thing remains true regardless of these advances: human judgment is still irreplaceable for the accuracy and contextual nuance that high-stakes AI applications demand.
Final Thoughts
Data annotation isn’t a background task. It’s the foundation on which every reliable AI system is built.
Businesses that treat annotation as a strategic investment — rather than a commodity checkbox — build AI products that outperform, outlast, and outscale their competition.
In 2026, the most efficient path to high-quality training data is clear: partner with a specialized annotation provider that brings expertise, tooling, and scale you can’t replicate internally.
The quality of your AI starts with the quality of your labels.
Looking to scale your AI training data? Explore professional data annotation and labeling services at oursglobal.com.